Reminders, part 3: registration and login flow
One of the goals of the reminders project is to simplify everything as much as possible. That includes the login and registration processes and the auxiliary features that go with them like forgotten password resets, other password changes, and email changes as well as the actual reminder creation and completion. Sometimes it seems like the simplest things are the most complex; I've built login and registration forms before, but when you really get into it there are enough corner cases that it seemed prudent to diagram it all out and make sure I've got everything streamlined in all possible circumstances.
I originally thought of having a single form for either login or registration--if the user existed, they would be logged in, otherwise a new account could be created. Of course, it's not really a good idea to create a new account if the user just got their username wrong, those people need a message saying that the username they gave doesn't exist. I've seen applications of this that have a "I'm creating a new account/I'm logging in" toggle, but that seems inelegant and potentially confusing.
An alternative is to use the error message to say "that account doesn't exist, would you like to create it?" and then automatically create it using the entered username and password. This would still require a separate registration form, or at least the appearance of being a separate form, and this form should likewise redirect the user to log in where appropriate, or perhaps even just log them in without redirecting. Separating the forms matches the mental model and the convention of there being two separate activities, but the processes need to remain interconnected so it they are still streamlined for those users who have forgotten they have an account or don't pay very much attention to which form they're typing into.
Registration
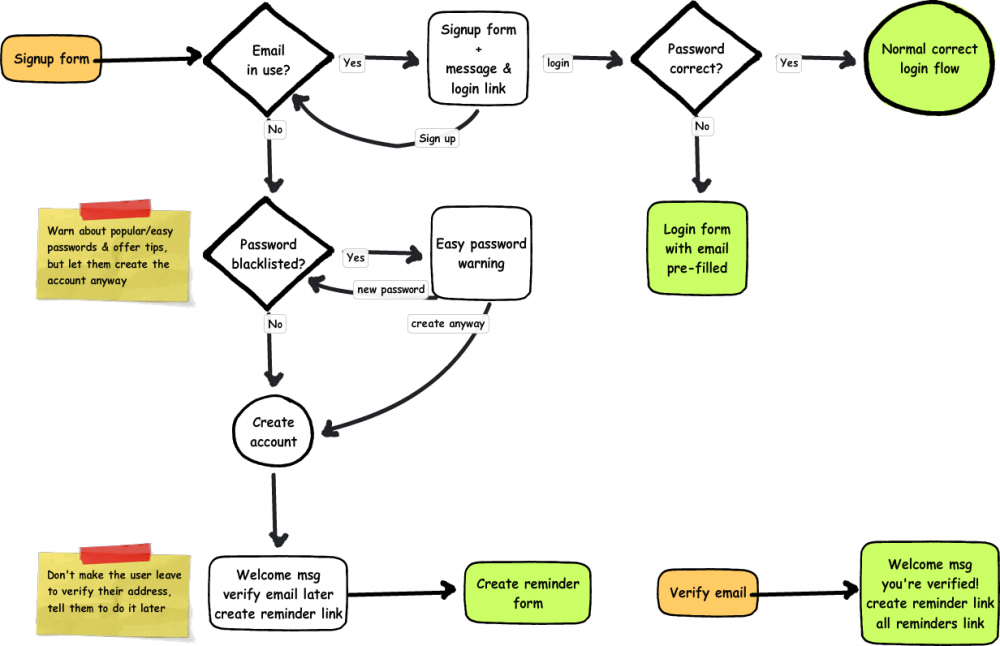
The registration form is going to be as simple as possible--an email address which will be used as a username, a password, and perhaps an "I'm over 13" checkbox as legally required. The email address should be unique per user, so if it's in use that user probably already has an account. Email verification is already necessary since the system may send out emails, so it should not be possible to use someone else's email address.
The simplest case is that the user comes to the registration form, enters an email that has never been used before and a good password, their account is created and a "verify your email" message is sent to that email address, and they are taken straight into creating reminders and asked to verify their email address later. Creating a reminder should also give them a warning about unverified email addresses.
The next use case is basically the same, but the user has entered a very common password like "1234". I believe that web developers have the responsibility to educate (but unobtrusively!) when users do something that may harm themselves, but also to allow them to do it if they really want to. To that end, I'm adding an additional registration step that warns the user that their password is one of the N most common, and could be guessed by a hacker in <10 seconds, for example. At that point the user can choose to use it anyway or pick a new one, at which point registration continues as before. This step would also be part of any process that involves changing a password.
It is also possible that the email address the user gives is already in use. Probably this is because they already have an account; if so, the user may also have given the password that belongs to that account, and can just be logged in according to the normal login process below. Otherwise, they will receive an error message that the email address given is in use and a link to log in, which will pre-fill the email address.
It is also possible that someone else registered the account, but in that case they would not have been able to verify the email address. Users can still log into an un-verified account, and they can have the password reset (described further below), so the legitimate owner of an email address should be able to gain control of an account registered to it. The simplest flow I have for that case is 1. try to create an account; 2. try to log in; 3. reset password. It's a little awkward to go through step 2 for an account the user never registered themselves, but for the most part step 2 is appropriate and it won't be appropriate to include a password reset link directly on the failed registration form. It may also be awkward to take over an account that someone else registered and added their own reminders to, but I'm not sure how to do that aside from requiring verification first, which is awkward for new users and affects a lot more people.
Being able to take over an account that is associated with your own email address is a good thing in the case mentioned above, but it could also be a bad thing if someone puts in an email address they do not use, it expires, and someone else takes it. Like anything else that uses email password resets, it will have to be the responsibility of the user to maintain a current email address on their account. If they really do use the account, logging in with an old email may serve as a reminder to update it, otherwise they may have to have a human verify that they own the account and change the email, and enough information needs to be logged that someone could do that.
Logging in
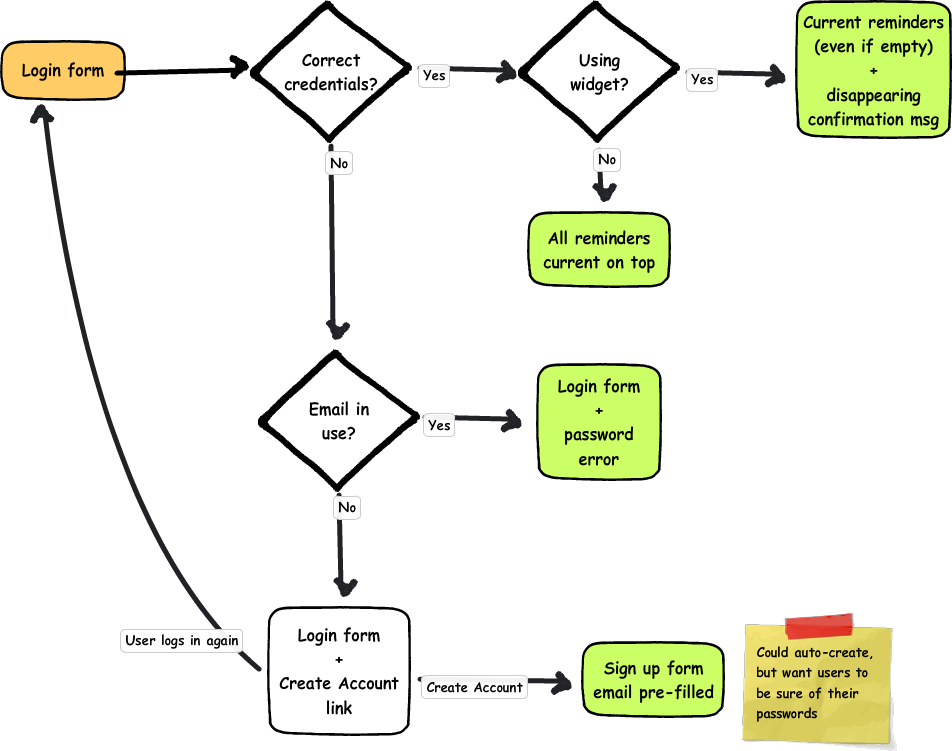
What happens when a user logs in depends on where they are logging in from. I'm still planning on having a desktop widget to show current tasks, so logging in on the widget will take take the user to the current tasks--even if it's empty--with a welcome back message that disappears after a moment on top. On the web, successfully logging in will take the user to a list of all their reminders with the tasks that come up soonest on top.
Many login forms make no distinction between username and password errors, they merely tell you that the combination of them is wrong. I've heard security cited as the reason for this--if it tells you that a username doesn't exist, then an automatic script can move onto the next username and try to crack that one's password. Personally, I think there are better methods of protecting users' accounts, and it's a better experience for the user if they know which field is wrong, so this login form will distinguish the two types of error.
If the email address the user provides does not exist, they will be told that the email does not exist and asked if they want to make a new account. If the user decides not to create a new account, they can enter a different email address and try logging in again.
Clicking a create account link could automatically generate an account with the password already provided, but I want to be sure that those users know they're creating an account and to be sure what their passwords are before continuing. Submitting the registration form takes the user into the registration process described in the previous section.
If the email address is in the system but the password is not correct, the user will be told that the entered password is incorrect and asked if they would like to have their password reset.
Forgotten passwords
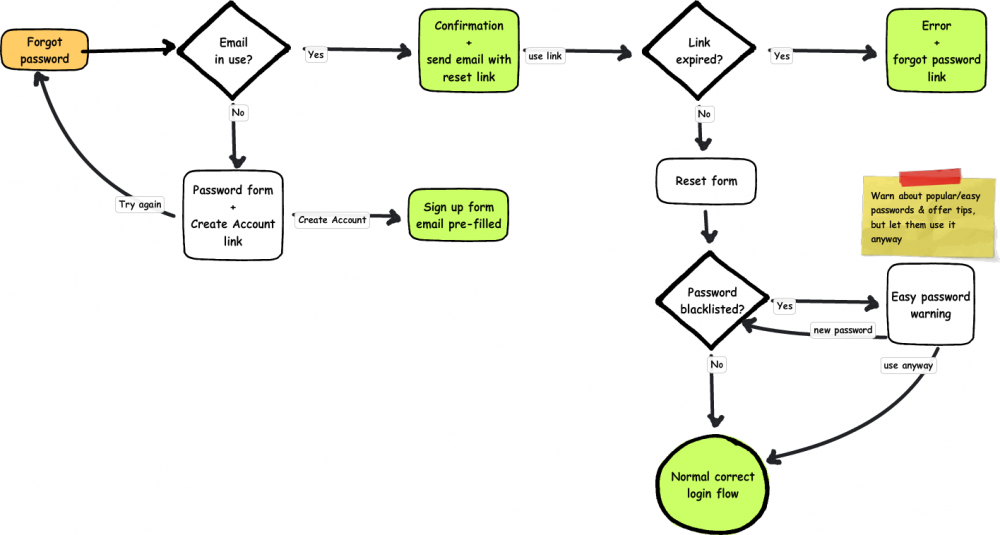
Resetting a user's password involves first sending a password reset link to a user's email, which they then must click on in a certain period of time to get the form to change their password. In the simplest scenario, the user finds the page from the login form, enters the email of an existing account, goes straight to their email and clicks the reset link, enters a good password, and is logged in.
Hopefully users won't click through to this page if they don't have an account, but they might still not know what email they used. If the email address is wrong, users are given an error and asked if they want to create an account just like the login, but I anticipate that fewer users will use it from this page.
Password reset links will have an expiration period for greater account security. If a user uses the link after that period of time they will be given a message telling them that it has expired and a new link has been emailed to them. Otherwise, the user will get a form with a password field, which will have the same password quality check as the signup form.
As mentioned before, it is possible to get into a state where you cannot reset your own password because you no longer have the email address associated with it. Those users will probably need to talk to someone to get their account back, but I have not yet decided where that fits into this flow. Perhaps it will just be in some informational text on the password reset page and on a separate support page.
Password changes
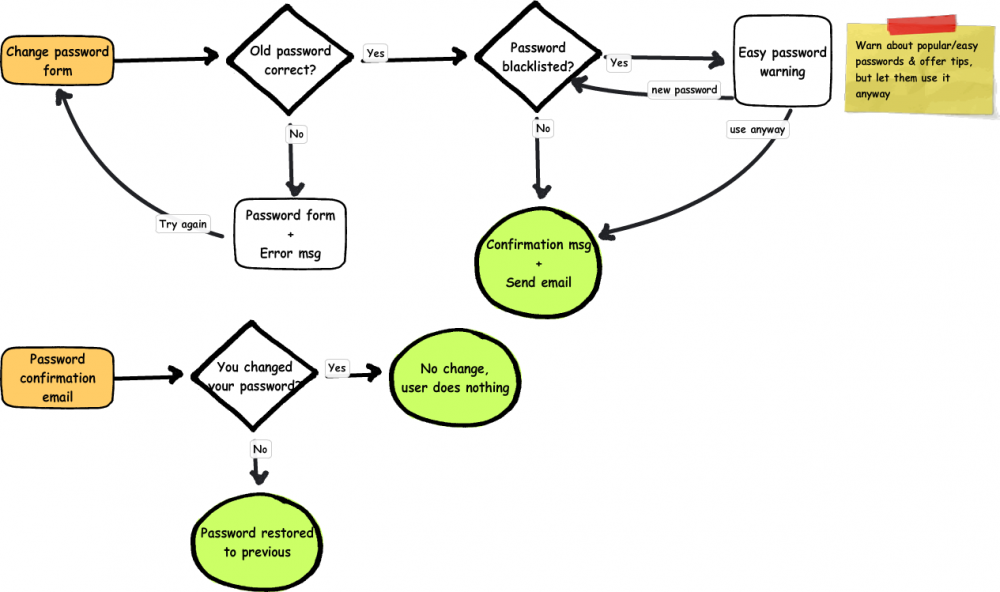
The normal password change process will be accessed by logged-in users, and requires the previous password instead of the user's email address. Like other methods of setting passwords, it will tell ask the user if they want to change a weak password but will not require them to.
Changing a password this way will also send the user an email, but if they actually did change their password they will not need to do anything with it. The email merely serves to warn users that their password is changed in case it was updated by someone else, and will allow them to set it back to what it was without having to know the new password.
Email changes
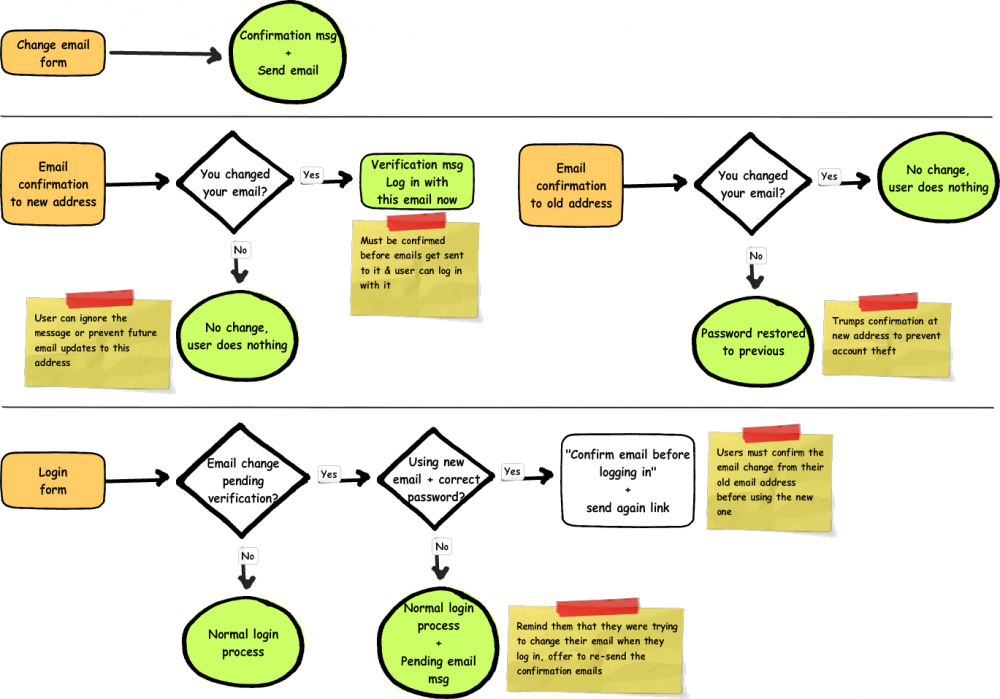
Changing email addresses is a little more complicated because it must be confirmed at both email addresses to prevent spam and account theft and because email is used to log in.
The basic email change form is simple, it just takes a new email address and responds with a confirmation message and sends two emails. The email to the old address is merely an alert like the password change message, it just gives the user a chance to set it back to what it was in the event that someone tried to set it for them. For the most part it can be ignored.
The email to the new address does require the user to confirm that this is their new address, both to prevent email to someone who doesn't want it and to make sure the email is correct so the user actually gets their reminders. If the new email is never confirmed, the system continues to use the old email.
I'm not quite sure how to handle unconfirmed email addresses when logging in. I think that maybe the login form should not accept the new email address until it is confirmed in case it belongs to someone else, but on the other hand unconfirmed email addresses are accepted for new accounts.
Regardless of whether or not the form allows the user to log in with the new email address, if the user has the password correct it should tell the user that they must confirm their new email address, and that the official address associated with the account will continue to be the old one until they confirm the new one. There should also be a link to re-send the confirmation email in case the old one has gotten lost or deleted.
It also ought to be possible to continue logging in with the old address until the new one is confirmed, since the new one really isn't official yet. Once the email is confirmed it's probably ok for it to be impossible to log in with the old one.
What's next?
The next step is probably to make a site map with all of these auxiliary pages to make sure I don't miss any, and wireframe or diagram any that I haven't done yet like account deletion. After that I can start on higher fidelity and full-page wireframes for the website and widget versions, and then maybe I can start on building things.